Krust AI Agent is designed for Kubernetes debugging, not chatbot demos. That means memory has to be fast, deterministic, and local-first.
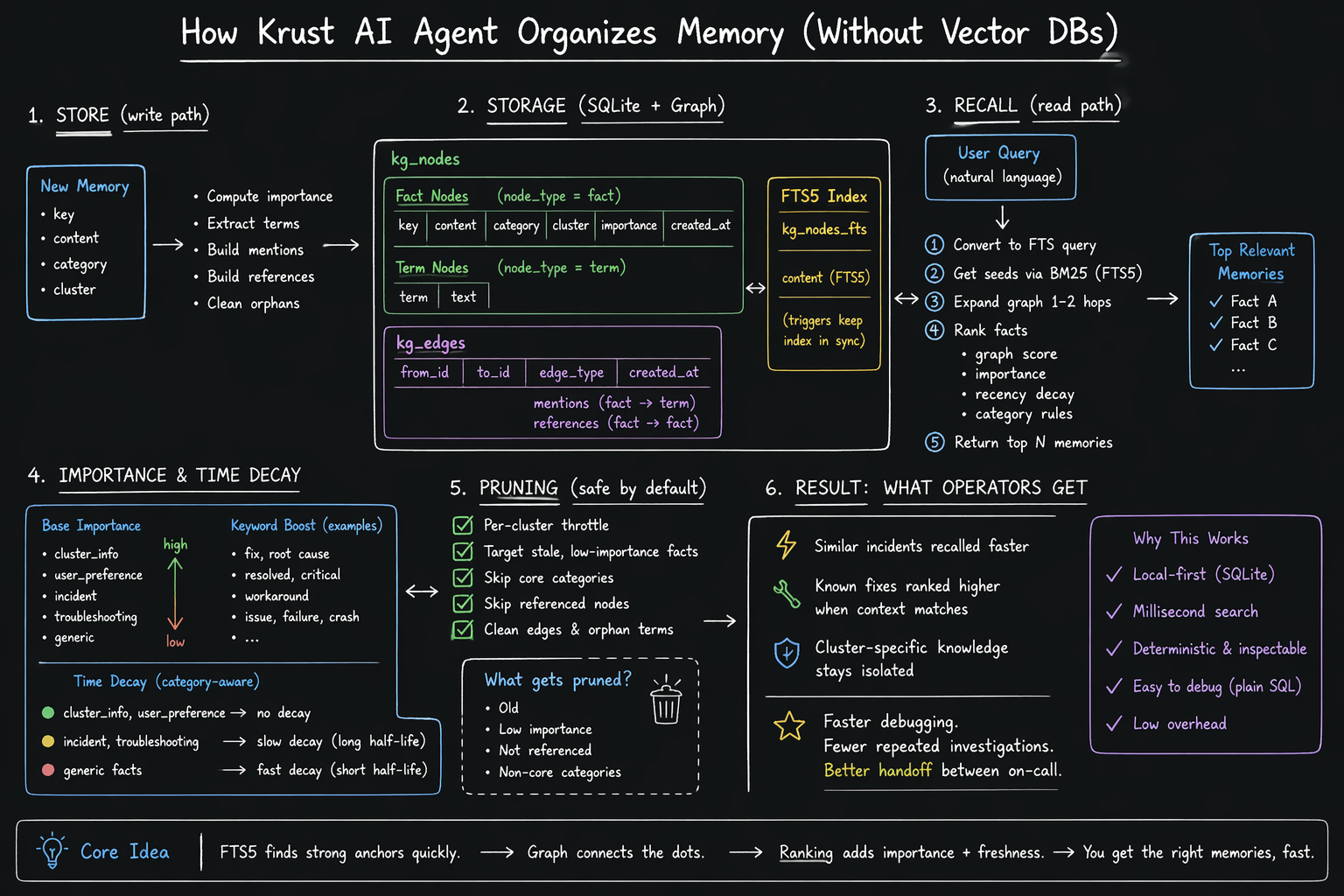
Instead of shipping embeddings + vector infrastructure, Krust uses a small GraphRAG-style memory system on top of SQLite. It is simple to operate, easy to inspect, and tuned for production incident workflows.
If you are new to the assistant, start with AI Agent docs.
Architecture overview used in this post.
Design Goals
The memory layer targets a few concrete outcomes:
- Keep everything local on your machine.
- Return relevant past findings in milliseconds.
- Prefer stable behavior over “maybe relevant” fuzzy recall.
- Age out stale low-value facts automatically.
- Stay debuggable with plain SQL.
This is why the implementation uses SQLite + FTS5 + graph edges, not a separate vector service.
Storage Model: Nodes + Edges
Krust stores memory in two core tables:
kg_nodes: fact and term nodeskg_edges: relationships between nodes
At a high level:
- A fact node is a memory item (
key,content,category,cluster,importance). - A term node is a token extracted from fact text.
mentionsedges connect fact -> term.referencesedges connect fact -> fact when content mentions other known keys.
FTS is maintained via kg_nodes_fts (SQLite FTS5) with triggers so text index stays in sync on insert/update/delete.
Why this shape works:
- FTS finds strong anchors quickly.
- Graph links expand context around those anchors.
- Ranking combines text relevance, graph proximity, importance, and freshness.
Write Path: What Happens on store()
When the agent stores memory:
- Upsert fact node by
(cluster, key, node_type=fact). - Compute
importancescore from category + high-signal keywords. - Rebuild
mentionsedges to extracted terms. - Build
referencesedges (max fan-out, skip noisy short keys). - Clean orphan term nodes.
Two useful details:
- Categories like
cluster_info,user_preference,incident,troubleshootinginfluence scoring and retention. - Auto-linking avoids unbounded graph growth by capping links and using conservative heuristics.
Result: each saved memory is structured enough for retrieval, but still lightweight.
Recall Path: FTS Anchor -> Graph Expansion -> Ranked Facts
Recall follows a strict flow:
- Convert query to FTS form.
- Get seed nodes via BM25 from
kg_nodes_fts. - Expand graph 1-2 hops through edges.
- Rank fact nodes with:
- graph score
- stored importance
- category-based recency decay
- Return top N entries.
Krust also supports scoped recall by cluster, plus all-cluster mode when needed.
This gives a practical balance:
- Better than pure keyword search (because it follows relationships).
- More deterministic and inspectable than black-box vector retrieval.
Importance and Time Decay
Krust does not treat all memories equally.
- Base importance comes from category.
- Keyword hits (
fix,root cause,resolved,critical, etc.) boost score. - Decay is category-aware:
cluster_infoanduser_preference: effectively no decayincidentandtroubleshooting: slower decay (longer half-life)- generic facts: faster decay
This keeps hard-earned operational knowledge visible while letting low-signal noise fade out.
Pruning Strategy (Safe by Default)
Memory pruning is conservative:
- Runs with per-cluster throttle (not constantly).
- Targets only stale, low-importance fact categories.
- Skips core categories and referenced nodes.
- Cleans related edges and orphan terms.
In short: prune garbage, keep context.
Why Not Use Embeddings?
Vector retrieval is powerful, but it adds complexity:
- embedding model lifecycle
- chunking/refresh policy
- indexing infra
- drift and reproducibility concerns
For Krust’s use case (cluster incidents, recurring patterns, short operational facts), SQLite graph memory is a good fit:
- simple deployment
- predictable behavior
- direct SQL debugging
- low overhead on developer machines
This is a product choice: optimize for reliability in day-to-day debugging, not benchmark novelty.
Practical Outcome for Operators
When you ask the agent to diagnose an issue, memory helps it avoid starting from zero:
- Similar incidents are recalled faster.
- Known fixes are ranked higher when context matches.
- Cluster-specific knowledge remains separate from other environments.
That means fewer repeated investigations and faster handoff between on-call sessions.
Where This Is Going Next
The current model is intentionally minimal and production-safe. Likely next steps are:
- Better edge semantics for causal chains.
- Stronger memory curation signals from user-confirmed resolutions.
- More explicit memory introspection in UI for auditability.
But the core principle stays: memory should help incident response without becoming another system you need to babysit.